
X-TEST 4K benchmark
Our method outperforms baseline methods on the X-TEST 4K benchmark, effectively handling challenging scenarios including large motion, repetitive textures, and thin structures.
We introduce HiFI, a patch-based cascaded pixel diffusion approach for High resolution Frame Interpolation, that generalizes across diverse resolutions up to 8K, a wide range of scene motions, and a broad spectrum of challenging scenes. HiFI helps significantly with high resolution and complex repeated textures that require global context. HiFI demonstrates comparable or beyond state-of-the-art performance on multiple benchmarks (Vimeo, Xiph, X-Test, SEPE-8K). On our newly introduced dataset that focuses on particularly challenging cases, HiFI significantly outperforms all other baselines.
Diffusion models are powerful but computationally very expensive. To scale up to 8K resolutions, we introduce a patch-based cascade model that always performs diffusion at the same resolution and upsamples by processing patches of the inputs and the prior solution. We show that this technique drastically reduces memory usage at inference time and also allows us to use a single model at test time, solving both frame interpolation (base model’s task) and spatial up-sampling, saving training cost.
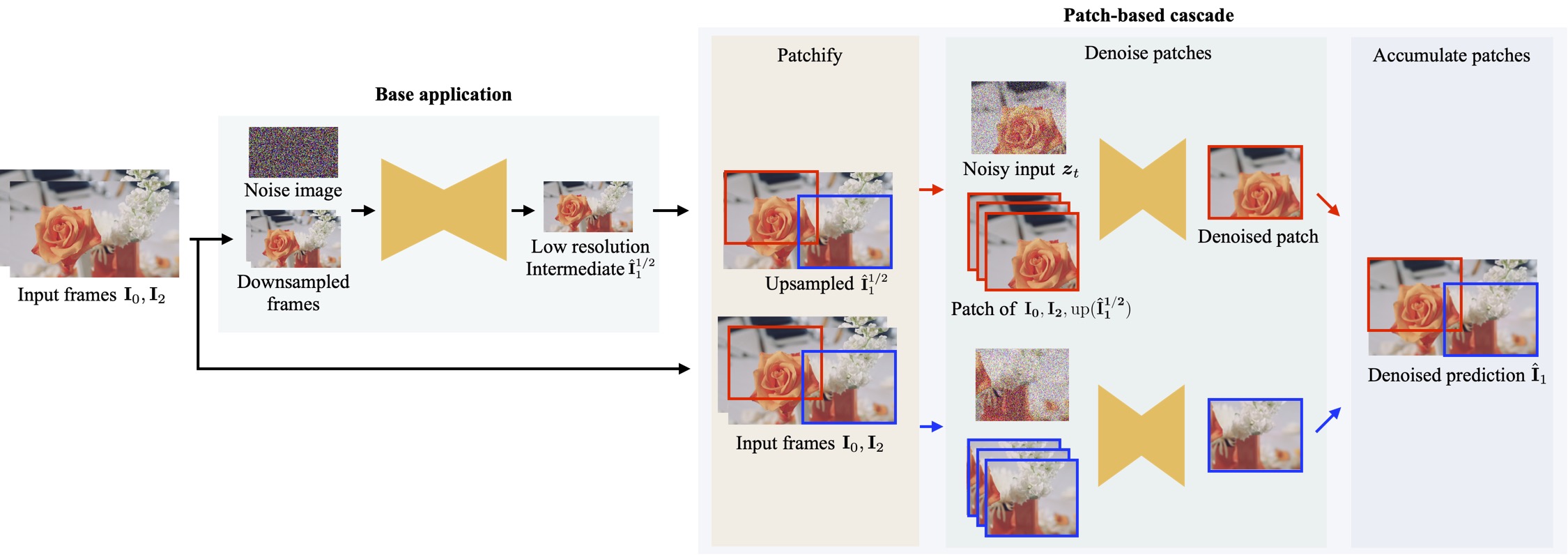
The input conditioning images are first downsampled to the lowest resolution. A low-resolution intermediate image is then generated through a denoising process. Then, at the original resolution, a patch-based cascade creates patches from the bilinearly upsampled low-resolution intermediate image and the two input frames. These patches then serve as conditioning for another denoising process. The denoised patches are combined to reconstruct the full image. This recursive, coarse-to-fine approach allows for high-resolution inference using a single, weight-shared model while maintaining near-constant peak memory usage during inference.
During training, we apply image-level dropout on the low-resolution intermediate conditioning so that the model can also serve as a base model when low-resolution intermediate conditioning is not applied.
@article{Hur:2025:HRF,
title = {High-Resolution Frame Interpolation with Patch-based Cascaded Diffusion},
author = {Hur, Junhwa and Herrmann, Charles and Saxena, Saurabh and Kontkanen, Janne and Lai, Wei-Sheng and Shih, Yichang and Rubinstein, Michael and Fleet, David J. and Sun, Deqing},
journal = {AAAI},
year = {2025},
}